【Python爬虫】微信公众号历史文章和文章评论API分析
本文共 10643 字,大约阅读时间需要 35 分钟。
上一篇文章介绍了微信公众号历史文章和文章评论API的组成情况,历史文章API格式:https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MjM5NjAxOTU4MA==&f=json&offset=10&count=10&is_ok=1&scene=126&uin=777&key=777&pass_ticket=tsN5weBAV13S7TjerqBeu0m84CMPMmPz4P7lb8bvDk90y1LP%2F1j46CUzFqDsMuRj&wxtoken=&appmsg_token=986_Zxzm8ptDJ39%252BC1UbkzPrFKd_laYeOCk5cVFX9A~~&x5=1&f=json
文章评论API格式:https://mp.weixin.qq.com/mp/appmsg_comment?action=getcomment&scene=0&__biz=MjM5NjAxOTU4MA==&appmsgid=3009217642&idx=2&comment_id=578089232589930496&offset=0&limit=100&uin=777&key=777&pass_ticket=v+7PaoESYfMrxgXJpqOkfXV4Y2+gYNPPJfSSmzPXfeiuNrNiBeEcs+8b//Yit5sd&wxtoken=777&devicetype=android-26&clientversion=2607033b&appmsg_token=986_jbuKqpV9lCZ1cb787Tem5V5n6JKpU9TrOFUZRE5esVxnBK7IR-TsZiXLRNaO1tnfx4rkIk1xyFHRlqI7&x5=1&f=json 这个两个API有些共同的参数:__biz,pass_ticket,公共参数可以通过抓包获取。 也有各自独有的参数:历史文章API中offset是一直变化的,appmsg_token也会随着时间失效,抓包可以获取appmsg_token,而offset是以0开始,可以通过API返回看到下一个offset是接口返回的字段“next_offset”值。

历史文章API返回的json信息:
下面是通过格式化后并删除一些不需要数据后的信息,json格式

文章评论API返回的json信息:
base_resp是返回状态情况,elected_comment才是评论的信息

elected_comment下面的详细信息,当评论有回复时,reply_list有信息

本文使用python3.6,pymysql连接mysql数据库,具体代码如下:
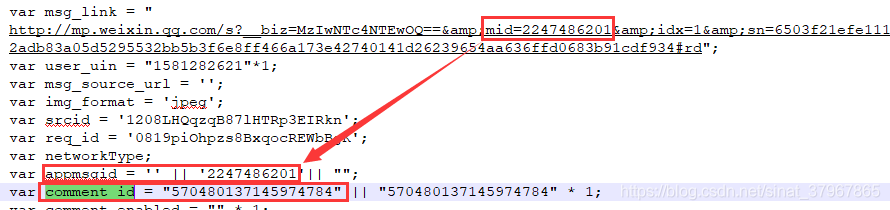
# -!- coding: utf-8 -!-'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''#作者:cacho_37967865#博客:https://blog.csdn.net/sinat_37967865#文件:wechatArticleList.py#日期:2018-12-08#备注:通过Fiddler抓包,获取微信公众号历史文章信息和文章评论信息存储到mysql数据库表 '''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''import requestsimport jsonimport pymysqlfrom datetime import datetimeimport reclass wechatArticle: def __init__(self,_biz,_pass_ticket,_appmsg_token,_cookie,_offset=0): self.offset = _offset # 不同公众号不一样 self.biz = _biz self.pass_ticket = _pass_ticket self.appmsg_token = _appmsg_token self.headers = { 'cookie':_cookie, 'User-Agent':'Mozilla/5.0 (Linux; Android 8.0; FRD-AL00 Build/HUAWEIFRD-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132' } self.db = pymysql.connect( host="localhost", user="root", password="123456", port=3306, use_unicode=True, #charset="utf8", database="sunshine") self.cursor = self.db.cursor() def get_article_list(self): offset = self.offset while True: api = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz={0}&f=json&offset={1}&count=10&is_ok=1&scene=126&uin=777&key=777&pass_ticket={2}&wxtoken=&appmsg_token={3}&x5=1&f=json'.format(self.biz, offset, self.pass_ticket, self.appmsg_token) resp = requests.get(api, headers=self.headers).json() print(type(resp), resp) # 字典类型 ret, status = resp.get('ret'), resp.get('errmsg') # 状态信息 if ret == 0 or status == 'ok': offset = resp['next_offset'] general_msg_list = resp['general_msg_list'] #print(type(general_msg_list),general_msg_list) # json类型 msg_list = json.loads(general_msg_list)['list'] # 先转化为字典类型再获取列表类型 for msg in msg_list: comm_msg_info = msg['comm_msg_info'] # 字典类型,每次推送的消息(一次三篇) msg_id = comm_msg_info['id'] # 推送消息的id post_time = datetime.fromtimestamp(comm_msg_info['datetime']) # 发布时间 try: app_msg_ext_info = msg['app_msg_ext_info'] # 字典类型,文章信息(一次三篇) first_article_id = app_msg_ext_info['fileid'] first_article_title = app_msg_ext_info['title'] # 本次推送的首条文章标题 first_article_digest = app_msg_ext_info['digest'] # 本次推送的首条文章摘要 first_article_url = app_msg_ext_info['content_url'] self.get_article_detail(first_article_id,first_article_url) first_url = first_article_url.replace('amp;', '').split('&chksm')[0] self.article_to_mysql(msg_id, first_article_id, first_article_title, first_article_digest,first_url, post_time) multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list') for article in multi_app_msg_item_list: article_id = article['fileid'] multi_article_title = article['title'] multi_article_digest = article['digest'] multi_article_url = article['content_url'] self.get_article_detail(article_id,multi_article_url) multi_url = multi_article_url.replace('amp;', '').split('&chksm')[0] self.article_to_mysql(msg_id, article_id, multi_article_title, multi_article_digest,multi_url, post_time) except Exception as f: print(str(f)) def get_article_detail(self,article_id,content_url): try: url = content_url.replace('amp;', '').replace('#wechat_redirect', '').replace('http', 'https') html = requests.get(url, headers=self.headers).text #print(html) except: print('获取评论失败' + content_url) else: str_comment = re.search(r'var comment_id = "(.*)" \|\| "(.*)" \* 1;', html) str_msg = re.search(r"var appmsgid = '' \|\| '(.*)'\|\|", html) # 文章的id str_token = re.search(r'window.appmsg_token = "(.*)";', html) if str_comment and str_msg and str_token: comment_id = str_comment.group(1) # 评论id(固定) app_msg_id = str_msg.group(1) # 票据id(非固定) appmsg_token = str_token.group(1) # 票据token(非固定) # 缺一不可 if comment_id and app_msg_id and appmsg_token: print("爬取评论的链接:" + url,html) self.get_article_comments(app_msg_id,comment_id,appmsg_token,article_id) def get_article_comments(self,app_msg_id,comment_id,appmsg_token,article_id): api = 'https://mp.weixin.qq.com/mp/appmsg_comment?action=getcomment&scene=0&__biz={0}&appmsgid={1}&idx=2&comment_id={2}&offset=0&limit=100&uin=777&key=777&pass_ticket={3}&wxtoken=777&devicetype=android-26&clientversion=2607033b&appmsg_token={4}&x5=1&f=json'.format( self.biz, app_msg_id, comment_id, self.pass_ticket, appmsg_token) resp = requests.get(api, headers=self.headers).json() ret, status = resp['base_resp']['ret'], resp['base_resp']['errmsg'] if ret =='0' or status == 'ok': elected_comment = resp['elected_comment'] for comment in elected_comment: content_id = comment.get('content_id') # 评论ID nick_name = comment.get('nick_name') # 评论人昵称 like_num = comment.get('like_num') # 点赞 comment_time = datetime.fromtimestamp(comment.get('create_time')) # 评论时间 content = comment.get('content') # 评论内容 #print("评论内容文章:",article_id,nick_name) self.comment_to_mysql(article_id,content_id,comment_time,nick_name,like_num,content) def create_article_table(self): sql1 = 'drop table if exists mnyd_article;' sql2 = 'create table mnyd_article(No INT(11) NOT NULL AUTO_INCREMENT,msg_id VARCHAR(15),article_id VARCHAR(15),post_time timestamp(2),title VARCHAR(200),digest VARCHAR(200),article_url varchar(300),PRIMARY KEY (No));' self.cursor.execute(sql1) self.cursor.execute(sql2) self.db.commit() def article_to_mysql(self,msg_id, article_id,title,digest,article_url,post_time): sql = "insert into mnyd_article(msg_id,article_id,title,digest,article_url,post_time) values('%s','%s','%s','%s','%s','%s')" % (msg_id,article_id,title, digest,article_url,post_time) try: # 使用 cursor() 方法创建一个游标对象 cursor self.cursor.execute(sql) except Exception as e: # 发生错误时回滚 self.db.rollback() print(str(e)) else: self.db.commit() # 事务提交 print('事务处理成功') def create_comment_table(self): sql1 = 'drop table if exists mnyd_comment;' sql2 = "create table mnyd_comment(No INT(11) NOT NULL AUTO_INCREMENT,article_id VARCHAR(15),content_id VARCHAR(20),comment_time timestamp(2),nick_name VARCHAR(50),like_num int,content varchar(1000),PRIMARY KEY (No)) COLLATE='utf8mb4_unicode_ci';" self.cursor.execute(sql1) self.cursor.execute(sql2) self.db.commit() def comment_to_mysql(self,article_id,content_id,comment_time,nick_name,like_num,content): sql = "insert into mnyd_comment(article_id,content_id,comment_time,nick_name,like_num,content) values('%s','%s','%s','%s','%i','%s')" % (article_id,content_id,comment_time, nick_name,like_num,content) try: # 使用 cursor() 方法创建一个游标对象 cursor self.cursor.execute(sql) except Exception as e: # 发生错误时回滚 self.db.rollback() print(str(e)) else: self.db.commit() # 事务提交 print('事务处理成功')if __name__ == '__main__': biz = 'MzIwNTc4NTEwOQ==' # "码农有道公众号" mnyd_article mnyd_comment pass_ticket = 'ZS3nqLX1df5GhZ+zf/t0FYyf7Nfp52yUJ+PuyJUKvQtyln78R3QzBU21Xo528IE+' app_msg_token = '986_G0Sy%252FL2pNlAGA9PIXcqTRipxsKaGLurexidEyg~~' # 历史文章 wap_sid2 = 'CL3qgfIFElxMOFBzZ2dZOHQ1WTcxamRQLXUyMGFiU0tvNkZzUEJmRURhZmtJTkhLcEtYWU9rNm5WYmUtd29qd3Q3UmVqbmpZXzFxS21GMG13amVjM1NEaUVPajZNZG9EQUFBfjDH8K3gBTgNQAE=' cookie = 'wxuin=1581282621; version=2607033b; pass_ticket={}; wap_sid2={}'.format(pass_ticket, wap_sid2) # 以上信息不同公众号每次抓取都需要借助抓包工具做修改 wxarticles = wechatArticle(biz, pass_ticket, app_msg_token, cookie) wxarticles.create_article_table() # 创建数据库表记录文章 wxarticles.create_comment_table() # 创建数据库表记录评论 wxarticles.get_article_list() # 开始爬取文章和评论 介绍一下上面的几个函数:
create_comment_table():创建存储评论的表,其中必须设置COLLATE='utf8mb4_unicode_ci',是为了确保能够存储特殊格式(mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。)的微信昵称到数据库。 get_article_list():获取历史文章的信息,存入到数据库,并且将文章id和文章链接传入到get_article_detail()函数 get_article_detail():根据get_article_list()函数传入的参数获取文章评论API的参数 get_article_comments():根据get_article_detail()函数传入的参数获取文章评论并存入到数据库此外注意以下几个要点:
def __init__(self,_biz,_pass_ticket,_appmsg_token,_cookie,_offset=0) 初始带cookie的参数信息,_offset=0对参数初始化 历史文章和文章评论API 可以通过str.format()设置参数 历史文章返回中有字段'app_msg_ext_info',在2017年5月前的文章是没有的,所以使用try.. except..这个时候我们已经获取到了需要的信息,后续就是对信息进行处理并转化为自己的东西。
你可能感兴趣的文章
pytorch(四)
查看>>
pytorch(5)
查看>>
pytorch(6)
查看>>
opencv 指定版本下载
查看>>
ubuntu相关
查看>>
C++ 调用json
查看>>
nano中设置脚本开机自启动
查看>>
动态库调动态库
查看>>
Kubernetes集群搭建之CNI-Flanneld部署篇
查看>>
k8s web终端连接工具
查看>>
手绘VS码绘(一):静态图绘制(码绘使用P5.js)
查看>>
手绘VS码绘(二):动态图绘制(码绘使用Processing)
查看>>
基于P5.js的“绘画系统”
查看>>
《达芬奇的人生密码》观后感
查看>>
论文翻译:《一个包容性设计的具体例子:聋人导向可访问性》
查看>>
基于“分形”编写的交互应用
查看>>
《融入动画技术的交互应用》主题博文推荐
查看>>
链睿和家乐福合作推出下一代零售业隐私保护技术
查看>>
Unifrax宣布新建SiFAB™生产线
查看>>
艾默生纪念谷轮™在空调和制冷领域的百年创新成就
查看>>